
A few days ago, Kaspersky published a blog post regarding a likely false flag in the wiper component of OlympicDestroyer. The attempt is based on an undocumented, lesser-known PE header called the RICH header. I don’t want to go into too much details regarding its layout, as many other sources have done a great job documenting it. Suffice it to say that this is an opaque structure added by Microsoft’s build environments during link time. If two programs have the same (or a very close) RICH header, one can assume that they were built in the same environment.
I had heard about this structure in the past and had been wanting to add support for it in Manalyze, as a way to improve the compiler detection beyond somewhat unreliable Yara rules. This was an opportunity to go back to it and look for additional ideas.
First of all, let’s look at one such header dumped from a sample executable (Notepad++):
RICH Header:
------------
XOR Key: 0x76456920
Unmarked objects: 0
241 (40116): 17
243 (40116): 173
242 (40116): 30
C++ objects (23013): 2
199 (41118): 5
ASM objects (VS2015 UPD3 build 24123): 24
C++ objects (VS2015 UPD3 build 24123): 122
C objects (VS2015 UPD3 build 24123): 37
Imports (VS2008 SP1 build 30729): 29
Total imports: 478
C++ objects (VS2015 UPD3.1 build 24215): 123
Resource objects (VS2015 UPD3 build 24210): 1
151: 26
Linker (VS2015 UPD3.1 build 24215): 1This calls for a few comments:
- The toolchain fingerprinting is based on its build number, and a few of them are missing in the example above. This implies that an effort needs to be made to curate the version information of all known VS components.
- Conversely, not all object types are recognized. This is because the same objects can have different identifiers between toolchains, so that’s another moving target. So far, I haven’t been able to identify a reliable source that lists them all.
- The
xorkey present in the structure is used to obfuscate it. It is derived from the contents of the DOS header and the RICH header itself, so it also acts as a checksum of sorts.
Initially, I guessed that this checksum was the way Kaspersky detected the false flag attempt. Due to the way it is calculated, it turns out not to be the case: the DOS header is mostly constant across files. However, thinking back, I figured it could be used to detect an antivirus bypass trick that was posted on Twitter a few months ago:
How to bypass 11 antivirus with 2 bytes (e.g.: capcom.sys) pic.twitter.com/VwhtsX3sqa
— zǝɹosum0x0 (@zerosum0x0) October 31, 2017
This is a simple, stupid, yet apparently effective way to decrease VT scores, just by altering the “This program cannot be run in DOS mode” string. Changing a single byte from it however renders the RICH checksum invalid and will now lead to the following message in Manalyze:
-------------------------------------------------------------------------------
~/Code/Manalyze/resources/tampered.exe
-------------------------------------------------------------------------------
Summary:
--------
Architecture: IMAGE_FILE_MACHINE_I386
Subsystem: IMAGE_SUBSYSTEM_WINDOWS_GUI
Compilation Date: 2016-Jul-25 00:55:51
Detected languages: English - United States
[ MALICIOUS ] The file headers were tampered with.
The RICH header checksum is invalid.Looking for other ideas, I stumbled upon this 2017 paper from Technische Universität München. What they’re doing is malware clustering based on the contents of the RICH header. They also propose two ideas to detect packed binaries based on “RICH corruption”:
- Validating the
xorkey, as I had done above. - Looking for duplicate entries, which apparently Visual Studio never causes. I have to admit I’m a little bit suspicious about this method, as I fail to imagine what kind of packer would make such modifications to the RICH header.
However, I noticed that this header contained the total number of imported functions and thought this might be a good way to see if the file was modified after the compilation step. I ran a few tests, and I ran into a high number of false positives. For some reason I haven’t been able to figure out, it’s quite common for the RICH header to report more imports than there actually are. However, I have yet to find a legitimate executable where the RICH header indicates less of them, so I’ve added this heuristic to Manalyze as well.
If we see a discrepancy between the reported number of imports and the actual one, we can make one of the two following hypotheses:
- The program has been packed and its
import address tablewas replaced. - The RICH header of the PE has been manually edited or does not belong to it.
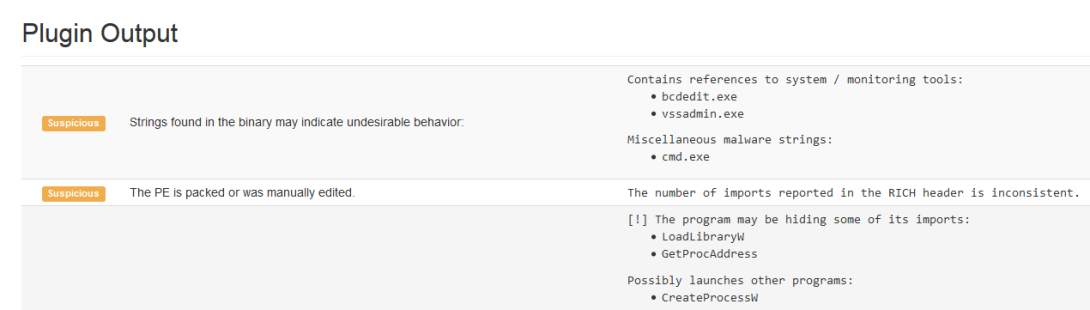
Here’s Manalyze’s output for the wiper described in Kaspersky’s article:
-------------------------------------------------------------------------------
~/Code/Manalyze/resources/3c0d740347b0362331c882c2dee96dbf
-------------------------------------------------------------------------------
Summary:
--------
Architecture: IMAGE_FILE_MACHINE_I386
Subsystem: IMAGE_SUBSYSTEM_WINDOWS_GUI
Compilation Date: 2017-Dec-27 09:03:48
Detected languages: English - United States
[ SUSPICIOUS ] The PE is packed or was manually edited.
The number of imports reported in the RICH header is inconsistent.To the best of my knowledge, this is an original finding, and I’m currently gathering files which exhibit this behavior. So far, here are a few I’ve located (excluding those with an invalid checksum):
0503715472705cf85e4fa4cb809ecfb2
085058177ea04280a513b60347e236f0
0b8626d51c731887a2f9ce62fda8cf90
0c831f7cea7366cc9830d4092ae00aa6
0f551179d77d1b9e4cad6f2ac9bdb523
0f60021361a248e490ac3d81d8f1f361
1828420081865bbc90d177a9f00ba4ac
1a14e6a962e0b086d589b967ae162328
200e8cbef605d45dcbb073ced92d6e0d While I haven’t looked into them at the moment, they all seem pretty suspicious from a static perspective. Let me know if you have other ideas on the subject!